可解释人工智能:概念、分类与负责任AI展望
论文信息
| 字段 | 内容 |
|---|---|
| 标题 | Explainable Artificial Intelligence (XAI): Concepts, Taxonomies, Opportunities and Challenges toward Responsible AI |
| 作者 | Alejandro Barredo Arrieta, Natalia Díaz-Rodríguez, Javier Del Ser, Adrien Bennetot, Siham Tabik, Alberto Barbado, Salvador Garcia, Sergio Gil-Lopez, Daniel Molina, Richard Benjamins, Raja Chatila, Francisco Herrera |
| 机构 | TECNALIA(西班牙)、ENSTA Paris、巴斯克大学、格拉纳达大学、Telefonica等 |
| 论文地址 | 发表于 Information Fusion |
| 发表时间 | 2019年12月 |
一句话概要
本文系统梳理了可解释人工智能(XAI)领域的核心概念、术语体系与最新进展。论文提出以"受众"为核心的新定义,并构建了涵盖透明模型与事后解释技术的双层分类法(~400篇文献)。在此基础上,论文识别出XAI面临的多项挑战,最终将讨论引向"负责任人工智能"框架,强调可解释性需与公平、隐私、问责等原则协同推进,为领域后续研究提供了系统的概念基础与分类参照。
背景与研究动机
人工智能系统正日益渗透到医疗、金融、法律、国防等高决策风险领域。论文指出,尽管深度学习等基于子符号主义的技术在性能上取得了突破性进展,但其内部机制——数百层网络与数百万参数——使其沦为典型的"黑箱模型"。这种黑箱属性构成了AI实际部署的核心障碍:用户难以信任、无法验证决策合理性、更无法在出现错误时进行有效的调试与纠正。
论文进一步指出,可解释性不仅是技术上的"附加需求",更是构建可信AI系统的必要条件。文中引用具体场景加以说明:在精准医疗中,医生需要比二元预测结果更丰富的信息来支撑诊断;在自动驾驶领域,系统决策的可理解性直接影响安全保障;而在监管合规方面,欧盟GDPR等法规已明确提出对算法决策的解释权要求。这些现实需求共同推动XAI从一个学术议题上升为产业落地的关键瓶颈。
值得注意的是,作者对XAI领域的活跃态势进行了量化展示:自2017年起,XAI相关文献数量呈爆发式增长,这说明研究界已普遍认识到这一问题的紧迫性。然而,正是这种快速发展的态势,加剧了领域内概念术语的混用与分类标准的不统一——这也是本文试图解决的起点性问题。
现有方法的瓶颈
论文在建立自身分类框架前,系统指出了前人工作的不足与局限:
第一,概念体系混乱,术语混用严重。 “interpretability"与"explainability"在大量文献中被互换使用,而"transparency”“comprehensibility”"understandability"等概念之间缺乏清晰边界。论文指出,即便是Gunning在DARPA项目中提出的经典XAI定义,也仅涵盖了"理解"与"信任"两个维度,忽略了因果性、可迁移性、信息性、公平性等重要目标。
第二,缺乏一个以"受众"为中心的统一定义框架。 绝大多数现有工作将可解释性视为模型的固有属性,忽略了"解释"行为本质上依赖于接收者的认知背景与需求。论文以语言哲学的视角指出:一个解释是否"清晰易懂",完全取决于受众。缺乏对这一维度的显式考虑,导致不同工作之间的结论难以比较。
第三,现有分类标准单一且不一致。 尽管已有少量综述尝试对XAI方法进行分类,但尚未形成统一的、覆盖从透明模型到事后技术全谱系的框架。论文指出,已有的分类大多仅聚焦于某一子领域(如深度学习或传统机器学习),缺乏跨模型的统一视角。
第四,XAI与数据隐私、安全、公平等维度的交叉研究几乎空白。 论文特别指出,可解释性的提升可能构成对模型机密性的威胁——反向工程攻击可借助解释信息重构模型参数;同时,多源数据融合场景下的可解释性-隐私权衡也几乎没有被讨论过。
可以理解为,这些局限点共同指向一个核心缺失:XAI领域缺少一个既能统摄现有工作、又能指导未来研究的全局性概念底座与分类体系。这正是本论文试图填补的空白。
核心洞察与贡献
论文的核心洞察在于:可解释性不是模型自身的二元属性,而是模型与受众之间的交互结果。因此,构建XAI体系时,首先要明确"对谁解释"和"为何解释"。这一洞察将XAI从纯技术问题拓展为人机交互与社会科学交叉的系统工程问题。
基于此,论文的主要贡献可归结为以下几点:
-
提出以"受众"为核心的可解释性新定义。 论文将XAI重新定义为:"针对特定受众,可解释人工智能产生细节或理由,使其功能清晰或易于理解。"这一定义明确将受众的认知水平与需求纳入考量,是所有后续分类与讨论的逻辑起点。
-
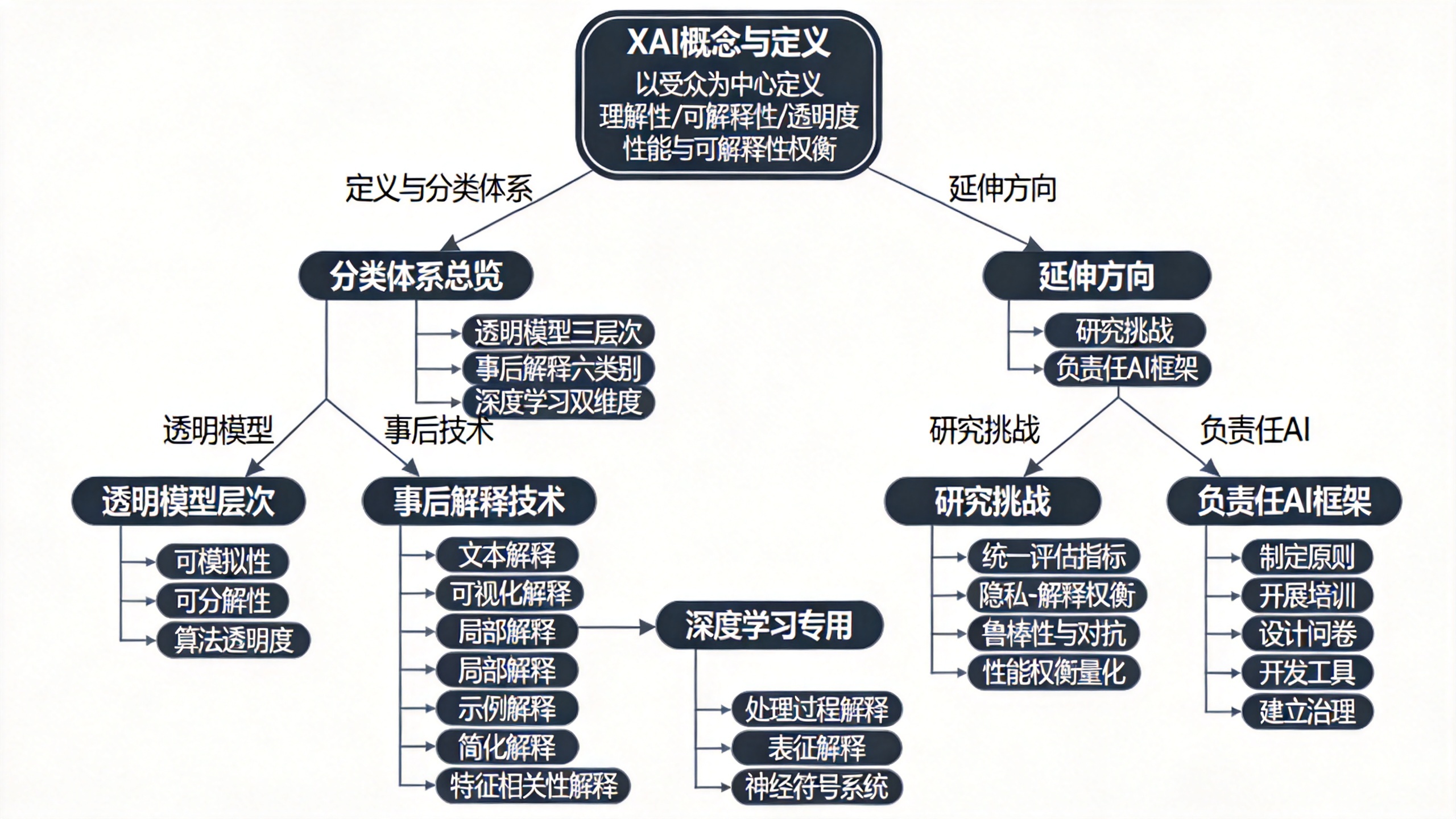
构建了涵盖透明模型与事后解释的双层分类法。 第一层区分"透明模型"(自身具备可理解性)与"事后可解释性"(对黑箱模型施加外部解释手段)。透明模型进一步细分为三个层次:可模拟性、可分解性与算法透明度;事后技术则划分为文本解释、可视化、局部解释、示例解释、简化解释与特征相关性六类。
-
专门为深度学习模型设计了第二套分类法。 考虑到深度学习技术的独特结构与巨大影响力,论文从"处理过程解释"与"表征解释"两个互补维度对其进行归类,并关联了注意力机制、神经符号系统等前沿方向。
-
系统梳理了XAI面临的若干未被充分关注的研究挑战。 包括:可解释性-性能权衡的量化、统一评估指标的缺失、鲁棒性与对抗样本的交互、数据融合场景下的隐私-解释权衡等。
-
提出"负责任人工智能"框架,将可解释性嵌入更广泛的AI伦理体系。 论文主张,可解释性不能孤立追求,必须与公平性、隐私保护、问责机制等原则协同推进,才能实现AI在真实组织中的大规模负责任部署。
值得注意的是,以上每一条贡献都直接回应了前文指出的某一特定瓶颈:新定义对标概念混乱,双层分类法对标分类标准缺失,深度学习分类法填补子领域覆盖不足,负责任框架引入了跨维度整合视角。
方法详解
核心概念框架
论文首先澄清了术语体系。其核心区分如下:
- 理解性(Understandability): 模型使人类理解其功能的能力,是最基本的概念。
- 可解释性(Interpretability): 提供意义与解释的能力,是模型的被动特征。
- 可解释性(Explainability): 模型主动采取行动来阐明或详述内部功能,是主动特征。
- 透明度(Transparency): 模型自身可被理解的特性,包含三个层次。
这三个透明度层次的递进关系是理解全文的关键。论文以图示化的方式阐明:可模拟性 > 可分解性 > 算法透明度,即满足可模拟性的模型必然同时具备后两者,反之则不成立。
可模拟性指人类能够在思维中完整地模拟模型的工作过程。这要求模型规模足够小、特征足够直观——例如,一个简单的线性回归模型或小型的决策树。可分解性要求模型的每个部分(输入、参数、计算)都可独立解释。例如,特征必须是人类可理解的,不能是高度工程化的抽象表示。算法透明度则仅要求用户能从数学上理解模型的优化与推理过程——例如,理解随机梯度下降在复杂神经网络中的作用机制,尽管无法追踪每个参数的贡献。
事后可解释性技术分类
对于不满足透明度标准的模型,论文将其解释手段分为六大类:
- 文本解释: 生成符号或自然语言来描述模型行为,例如"因为特征x2大于180,所以预测为正类"。
- 可视化解释: 通过热力图、显著性图等技术展示模型关注区域,常用于CNNs。
- 局部解释: 仅解释模型在某一输入邻近区域的行为,代表性方法如LIME。
- 示例解释: 提取最具代表性的数据样例来解释模型决策,如基于最近邻的解释。
- 简化解释: 训练一个更简单的代理模型来近似黑箱模型的行为,如规则提取方法G-REX。
- 特征相关性解释: 计算每个输入特征对输出的贡献度,代表性方法如SHAP。
论文明确指出,这六类技术并非互斥,实际应用中往往混合使用。例如,LIME同时属于局部解释与简化解释两个类别。
深度学习专用分类法
鉴于深度学习模型在XAI文献中占比显著,论文构建了第二套分类法,核心区分了两个维度:
对深度网络处理过程的解释,回答"为什么这个特定输入导致这个输出?"。其下包括:线性代理模型、决策树近似、自动规则提取、显著性映射、局部解释、层次角色分析、文本解释等。
对深度网络内部表征的解释,回答"网络内部包含什么信息?"。涉及:单个神经元行为分析、表征向量的角色、注意力机制、特征相关性、表征解缠等。
此外,论文将"解释生成系统"与"混合透明-黑箱方法"作为单独类别加入分类法。其中值得特别关注的是神经符号系统——论文认为,结合连接主义与符号主义范式是实现真正可解释深度学习的最有前景方向之一:连接主义保证性能,符号主义提供结构化的、可推理的解释。
文献分析与评估
分类框架的合理性与价值
论文对约400篇文献的分类工作是其核心贡献之一。从方法学的角度评估,该分类框架具有以下特点:
覆盖面广:从线性回归、决策树等透明模型,到支持向量机、树集成、多层神经网络、CNN、RNN等黑箱模型,再到模型无关的事后技术,基本囊括了主流ML模型的解释方法。这种全谱系覆盖为初学者提供了清晰的全局视图。
层次清晰:在透明模型一侧,论文摒弃了简单的"透明vs不透明"二分法,引入三个递进层次(可模拟、可分解、算法透明),这为评估模型的可解释性程度提供了更精细的刻度。例如,一个层数较多的决策树可能仍具有算法透明度,但已丧失可模拟性。
深度学习专用分类法具有前瞻性:将"处理过程解释"与"表征解释"区分开来,呼应了程序设计中"执行轨迹"与"数据结构"的类比,为XAI方法的选择提供了决策依据——当需要理解模型如何做出特定预测时,应选择处理过程解释方法;当需要理解模型学习到了什么概念时,应选择表征解释方法。
文献覆盖的局限
尽管覆盖面广,但论文自身的局限性同样值得关注。首先,文献收集的截止时间为2019年12月,这意味着2019年底至2020年间迅速发展的技术(如ChatGPT系列中的解释机制、大规模语言模型的提示解释等)未被纳入。这在综述性论文中属于不可避免的时间切片问题,但读者在参考分类框架时应意识到这一点。
其次,论文对文献的归类标准存在一定主观性。例如,LIME被同时归入"简化解释"与"局部解释",这在分类学上虽有合理性,但使得不同类别之间的边界并非完全互斥。论文对此有所预判,指出这种重叠是分类框架的固有特性而非缺陷——不同的分类角度服务于不同的理解需求。
批判性观点的价值
论文并非仅做文献罗列,而是明确提出了若干批判性判断。例如,论文指出局部解释方法在深度网络中强烈受到底层特征的主导,这意味着它们可能无法揭示模型的高层语义决策逻辑。这一判断已被后来许多工作(如Adebayo等人的saliency map sanity checks)进一步验证。
另一个有价值的批判是论文对可解释性-性能权衡的重新审视。论文引用了Rudin等人的论点指出:“更复杂的模型未必更准确”——当数据结构化良好且特征质量高时,简单模型可能达到与复杂模型相近的精度,同时保持可解释性。这意味着"权衡"的发生有其前提条件,而非普遍规律。
优势与局限性
优势
系统性极强。 在整个XAI领域尚处萌芽与快速增长期之际,本文提供了迄今为止最全面的概念净化与分类集成工作之一。新定义将"受众"置于核心位置,这一视角在后续XAI研究中(如人机交互与XAI的交叉领域)产生了深远影响。
跨域关联意识突出。 论文明确指出了XAI与数据融合、联邦学习、多元视图学习等技术的交互,这些都是当时研究社区尚未充分探索的交叉地带。特别是关于XAI可能威胁数据隐私与模型机密性的讨论,在GDPR全面生效的背景下具有极高的现实意义。
负责任AI框架提出了实操性指南。 论文不仅定义了概念,还给出了在组织中实施负责任AI的推荐步骤:制定原则→开展培训→设计问卷→开发工具→建立治理模型。这种从理论到实践的推演,提升了论文的应用价值。
局限性
缺乏统一的评估方法论。 论文虽然明确指出了"需要通用可解释性度量"这一挑战,但自身并未提出量化的评估指标或实验验证框架。这可以理解为综述性论文在方法论建构上的共同局限——指路与修路是不同阶段的任务。
对某些技术的讨论深度有限。 例如,对抗性攻击与XAI的交互被作为独立小节讨论,但主要集中在概念层面的风险提示,未深入分析具体攻击方法(如FGSM、PGD)与解释方法之间的相互作用机制。
可复现性有限。 作为综述,论文不以可复现为主要目标。但其引用的约400篇文献均给出了完整来源,读者可按图索骥追查原始方法与实验。论文本身不涉及代码或数据集的发布。
结论的可推广性需谨慎评估。 论文将XAI的最终归宿指向"负责任AI",这一判断建立在对西欧与美国AI伦理原则的集中分析基础上。不同文化背景与法律框架下的AI治理范式可能不同,这意味着"负责任AI"的构成要素及其权重可能存在地域差异。
未来方向与开放问题
论文自身提出了若干值得跟进的研究方向,侧重于XAI子领域内部的深化,而非泛泛而论:
建立统一的可解释性度量体系是当务之急。 论文指出,没有度量工具,任何关于"模型是否可解释"的主张都难以量化比较。从社会认知科学的心理学实验方法中汲取灵感,将人类研究(human-grounded evaluation)的范式纳入XAI评估,是论文建议的方向。例如,可以通过对比"设计良好的解释"与"随机解释"对用户决策效率的提升来量化解释质量。
深度学习模型的可解释性仍是最关键战役。 论文建议从以下几个子方向切入:利用神经符号系统结合连接主义与符号主义、通过注意力机制提供自然解释、发展基于生成对抗网络或变分自编码器的反事实解释方法。此外,论文特别强调:好的解释应该具备"建构性"(不仅解释为何做出决策X,还解释为何不做决策Y)和"选择性"(聚焦于主要因果链),这为设计者指明了原则性标准。
XAI与数据融合的交汇是一个几乎未被探索的领域。 论文以联邦学习为例提出了一个尖锐问题:共享模型梯度可能使局部节点的隐私信息通过逆向分析被重构,而XAI技术如果应用在聚合模型上,是否会进一步加剧这种隐私泄露?这是一个亟待实证研究的开放问题。
XAI与公平性的交叉也需要更多方法论贡献。 论文指出,现有的偏差检测方法(如通过SHAP生成反事实解释来检测敏感特征与非敏感特征之间的隐式关联)仍处于概念验证阶段,需要更系统化的框架来指导实践。
组会预判问答
Q1: 论文提出的新定义是否真正超越了已有的定义? 论文认为,将"受众"显式纳入定义是其核心贡献。这一定义的优势在于:它暗示了可解释性不是绝对属性,而是相对属性。但这一定义也带来了操作上的复杂性——如何针对不同受众定制解释?论文并未给出具体实施方案。可以理解为,这是方向性的指引而非操作性方案。
Q2: 两个分类法之间的关系是什么?是否有冗余或冲突? 论文明确指出了两套分类法之间的互补与重叠关系。第一套(Figure 6)基于"模型类型×解释技术"的二维矩阵,面向所有ML模型;第二套(Figure 11)则从"解释目标"(处理过程vs.表征)出发,专为DL设计。重叠之处在于:某些方法(如Layer-wise Relevance Propagation)在两种分类中都会出现,但归类视角不同——一个按技术类型(特征相关性),一个按解释目标(处理过程)。
Q3: 文中提到的"可解释性-性能权衡"是否真的存在?论文对此采取了什么立场? 论文借Rudin等人的论点指出该权衡并非必然成立:当数据质量足够高、问题本身不太复杂时,透明模型可能达到与复杂模型相近的性能。因此,论文的立场是:建议在可能的情况下优先选择透明模型,将黑箱模型作为备选,仅在透明模型无法满足性能需求时才启用,并辅以后事解释技术。这与其他一些XAI综述中默认"权衡不可避免"的立场有所不同,体现了论文本土化的批判性。
Q4: 论文对深度学习模型的分类与文献的实际覆盖是否一致?是否存在重要遗漏? 最明显的时序遗漏是2020年后的发展(如大规模语言模型的解释方法)。但就2019年及之前的文献而言,论文对CNN和RNN的覆盖相对充分。对其评价值的判断是:单层与多层MLPs的相关文献覆盖较全,但GRU/LSTM的某些特殊变体(如Tree-LSTM)的解释方法未被单独讨论。
Q5: "负责任AI"框架在实践中的可操作性如何? 论文提出的实施步骤(原则制定→培训→问卷→工具→治理)给出了逻辑链条,但其具体细节依赖组织自身的资源与流程。一个关键挑战在于:不同原则之间可能发生冲突(例如,强化解释可能削弱隐私保护)。论文承认了这一张力,但未给出冲突解决机制的具体建议。可以理解为,负责任AI在当前阶段更多的是指导性愿景而非可执行的标准操作程序。
本报告由立理AI生成,仅供参考,请以原文为准。